


Image credit: Cormullion, Julia code here.
π (Pi) is the mathematical constant that represents the ratio of a circle’s circumference to its diameter.
\[\pi = \frac{\text{circumference}}{\text{diameter}}\]
Its approximate value is: \(\pi \approx 3.14159265358979323846\ldots\)
Properties of π
- Irrational: π cannot be expressed as a fraction of two integers.
- Transcendental: π is not the root of any polynomial equation with rational coefficients.
- Infinite Digits: π never terminates or repeats in decimal form.
- Ubiquitous in Mathematics: Found in geometry, trigonometry, calculus, physics, and statistics.
One of the best ways to test the performance of a new computer is to compute π to a large number of digits. The most efficient way to compute digits of π is to use the Chudnovsky algorithm developed in 1987 by David and Gregory Chudnovsky.
\[\frac{1}{\pi} = 12 \sum_{k=0}^{\infty} \frac{(-1)^k (6k)! (545140134k + 13591409)} {(3k)! (k!)^3 (640320)^{3k + 3/2}}\]
Each term adds around 14 decimal digits of π, making it the fastest known series for computing π.
Note: From a practical perspective, what would be the maximum number of digits ever needed? To compute the circumference of the universe in the smallest possible units of Angstroms, we need to know π to about 39 digits.
Computing π
To compute π to a larger number of digits we need a multi-precision math library. The GNU C++ compiler has a multi-precision integer library called GMP (GNU Multiple Precision) and a multi-precision floating point library based on GMP called MPFR (Multiple Precision Floating-Point Reliable). Both of these use C-style function calls. GMP also has a C++ wrapper interface that is easier to use. MPFR doesn't come with a similar wrapper class for C++ but there is one available called mpreal.h that you can download and use with MPFR.
The following program uses MPFR and OpenMP to distribute the computation of terms across multiple threads. Each term is computed and added to a thread local sum that will later combined into a total sum when all threads are complete.
pi_chudnovsky.cpp
/**
* @file pi_chudnovsky.cpp
* @brief Program to compute π.
*
* This program can compute π using the Chudnovsky algorithm.
*
* Syntax: pi_chudnovsky_fast <num_digits>
*
* get mpreal.h at https://github.com/advanpix/mpreal.git
*
* Compile with command:
* MacOS: Apple Clang doesn't support OpenMP but homebrew does
* put mpreal.h in /opt/homebrew/include
* brew install gcc
* brew install gmp
* brew install mpfr
* g++-14 -I/opt/homebrew/include -L/opt/homebrew/lib -o pi_chudnovsky pi_chudnovsky.cpp -lmpfr -lgmp -fopenmp
*
* Linux
* put mpreal.h in /urs/local/include
* sudo apt install libgmp-dev
* sudo apt install libmpfr-dev
* g++ -o pi_chudnovsky pi_chudnovsky.cpp -lmpfr -lgmp -fopenmp
*
* @author Richard Lesh
* @date 2025-03-16
* @version 1.0
*/
#include <gmpxx.h> // GMP C++ Wrapper
#include <iomanip>
#include <iostream>
#include <mpreal.h> // MPFR C++ Wrapper
#include <omp.h> // OpenMP
#include <thread>
int DIGITS = 50;
int PRECISION;
int NUM_TERMS;
int NUM_THREADS = 4; // Adjust based on CPU cores
using namespace mpfr;
using namespace std;
/**
* @brief Compute π.
*
* Function to compute π using the Chudnovsky algorithm.
*
* @return mpreal A multi-precision value for π.
*/
mpreal compute_pi_chudnovsky() {
mpreal::set_default_prec(PRECISION); // Set default precision in bits
// Thread local storage for the partial sums computed in that thread
mpreal partial_sums[NUM_THREADS];
// Parallel computation of series sum
#pragma omp parallel for num_threads(NUM_THREADS) schedule(dynamic)
for (int k = 0; k < NUM_TERMS; k++) {
// Set default precision in bits for each thread
mpreal::set_default_prec(PRECISION);
int tid = omp_get_thread_num();
// Local GMP variables for factorials
mpz_class k_fact, three_k_fact, six_k_fact;
// Compute factorials
mpz_fac_ui(k_fact.get_mpz_t(), k);
mpz_fac_ui(three_k_fact.get_mpz_t(), 3 * k);
mpz_fac_ui(six_k_fact.get_mpz_t(), 6 * k);
// Compute numerator: +- (6k)! * (545140134 * k + 13591409)
mpz_class numerator = six_k_fact * (mpz_class(545140134) * k + mpz_class(13591409));
// Apply alternating sign (-1)^k
if (k % 2 != 0) mpz_neg(numerator.get_mpz_t(), numerator.get_mpz_t()); ;
// Compute denominator: (3k)! * (k!)^3 * (640320^(3k+3/2))
mpreal denominator = pow(mpreal(640320), 3.0 * k + 1.5);
denominator = denominator * mpz_class(three_k_fact * k_fact * k_fact * k_fact).get_mpz_t();
// Ensure denominator is never zero
if (denominator == 0) {
std::cerr << "Error: Division by zero at k = " << k << std::endl;
exit(1);
}
// Compute term: numerator / denominator
mpreal term = numerator.get_mpz_t() / denominator;
// Accumulate thread-local sum
partial_sums[tid] += term;
}
mpreal sum(0);
// Reduce all thread-local sums into a single sum
for (int i = 0; i < NUM_THREADS; i++) {
sum += partial_sums[i];
}
// Compute final pi: pi = 1 / (sum * 12)
mpreal pi = 1 / (sum * 12);
return pi;
}
/**
* @brief Main function.
*
* The entry point of the program. It handles command-line arguments
* setting up global settings and timing the computation.
*
* @return int Returns 0 on successful execution.
*/
int main(int argc, char **argv) {
if (argc > 1)
DIGITS = atoi(argv[1]);
PRECISION = (DIGITS * 4); // Precision in bits (~3.3 decimal digits per bit)
NUM_TERMS = (DIGITS / 14 + 2); // each additional term contributes about 14.18 decimal digits to π
if (std::thread::hardware_concurrency() != 0)
NUM_THREADS = std::thread::hardware_concurrency();
double start_time = omp_get_wtime();
mpreal pi = compute_pi_chudnovsky();
double end_time = omp_get_wtime();
cout << setprecision(DIGITS) << pi << endl;
printf("Computation Time: %f seconds\n", end_time - start_time);
return 0;
}
We can make this program significantly faster by avoiding the computation of all the factorials and powers from scratch for each term in the series. If we can figure out how one term in the series relates to a previous term we can reduce the number of multiplies and divides. So assume that there is a factor ƒ such that:
\[t_{k + n} = ƒ_{k,n} \cdot t_k\]
where \(t_k\) is the kth term in the series and \(t_{k + n}\) is a later term in the series n terms beyond \(t_k\).
So this factor \(ƒ_{k,n}\) is:
\[ƒ_{k,n} = \frac{t_{k + n}}{t_k}\]
if we substitute
\[t_{k + n} = \frac{(6k+n)! \cdot (545140134(k+n)+13591409)}{(3(k+n))! \cdot ((k+n)!)^3 \cdot (640320)^{3(k+n)+1.5}}\]
and
\[t_k = \frac{(6k)! \cdot (545140134k+13591409)}{(3k)! \cdot (k!)^3 \cdot (640320)^{3k+1.5}}\]
we get after simplifying
\[ƒ_{k,n} = \frac{\prod_{i=1}^{n} (6k+i)}{\left[ \prod_{i=1}^{3n} (3k+i) \right] \cdot \left( \prod_{i=1}^{n} (k+i) \right)^3} \cdot \left(1 + \frac{545140134n}{545140134k+13591409}\right) \cdot \frac{1}{(640320)^{3n}}\]
where \(\prod_{i=1}^{n}x\) represents the factorial ratio of \(\frac{(x+n)!}{x!}\).
\[\prod_{i=1}^{n}x = \frac{(x+n)!}{x!} = (x + 1)\cdot(x + 2) \dots (x +n)\]
By computing factorial ratios we only multiply the last few factors of a factorial instead of multiplying all the factors that it takes to compute individual factorials. This saves us a lot of time. So our strategy is to use the full Chudnovsky formula for the first term, then simply calculate the factor \(ƒ_{k,n}\) for successive terms so that we can multiply the factor by the previous term that we have already computed.
pi_chudnovsky_fast.cpp
/**
* @file pi_chudnovsky_fast.cpp
* @brief Program to compute π.
*
* This program can compute π using the Chudnovsky algorithm.
*
* Syntax: pi_chudnovsky_fast <num_digits>
*
* get mpreal.h at https://github.com/advanpix/mpreal.git
*
* Compile with command:
* MacOS: Apple Clang doesn't support OpenMP but homebrew does
* put mpreal.h in /opt/homebrew/include
* brew install gcc
* brew install gmp
* brew install mpfr
* g++-14 -I/opt/homebrew/include -L/opt/homebrew/lib -o pi_chudnovsky_fast pi_chudnovsky_fast.cpp -lmpfr -lgmp -fopenmp
*
* Linux
* put mpreal.h in /urs/local/include
* sudo apt install libgmp-dev
* sudo apt install libmpfr-dev
* g++ -o pi_chudnovsky_fast pi_chudnovsky_fast.cpp -lmpfr -lgmp -fopenmp
*
* @author Richard Lesh
* @date 2025-03-16
* @version 1.0
*/
#include <gmpxx.h> // GMP C++ Wrapper
#include <iomanip>
#include <iostream>
#include <mpreal.h> // MPFR C++ Wrapper
#include <omp.h>
#include <thread>
int DIGITS = 50;
int PRECISION;
int NUM_TERMS;
int NUM_THREADS = 4; // Adjust based on CPU cores
using namespace mpfr;
using namespace std;
/**
* @brief Compute factorial ratio.
*
* Function to compute the ratio of two factorials.
* Efficiently computes num_n! / denom_n!
*
* @param num_n Larger of the two factorial n values
* @param denom_n Smaller of the two factorial n values
* @return mpreal A multi-precision value for factorial ratio.
*/
mpz_class factorial_ratio(long num_n, long denom_n) {
mpz_class result = 1;
for (long i = denom_n + 1; i <= num_n; ++i) result *= i;
return result;
}
/**
* @brief Compute π.
*
* Function to compute π using the Chudnovsky algorithm.
* Optimized to avoid computing terms from scratch each loop.
*
* @return mpreal A multi-precision value for π.
*/
mpreal compute_pi_chudnovsky() {
mpreal::set_default_prec(PRECISION); // Set default precision in bits
// thread local values
mpreal partial_sums[NUM_THREADS];
mpreal term[NUM_THREADS];
long previous_k[NUM_THREADS]; // Initialzed to 0 in C++11
// Parallel computation of series sum
#pragma omp parallel for num_threads(NUM_THREADS) schedule(dynamic)
for (long k = 0; k < NUM_TERMS; k++) {
// Set default precision in bits for each thread
mpreal::set_default_prec(PRECISION);
int tid = omp_get_thread_num();
// If no previous term has been computed use full formula
if (previous_k[tid] == 0) {
// Local GMP variables for factorials
mpz_class k_fact, three_k_fact, six_k_fact;
// Compute factorials
mpz_fac_ui(k_fact.get_mpz_t(), k);
mpz_fac_ui(three_k_fact.get_mpz_t(), 3 * k);
mpz_fac_ui(six_k_fact.get_mpz_t(), 6 * k);
// Compute numerator: +- (6k)! * (545140134 * k + 13591409)
mpz_class numerator = six_k_fact * (mpz_class(545140134) * k + mpz_class(13591409));
// Apply alternating sign (-1)^k
if (k % 2 != 0) mpz_neg(numerator.get_mpz_t(), numerator.get_mpz_t()); ;
// Compute denominator: (3k)! * (k!)^3 * (640320^(3k+3/2))
mpreal denominator = pow(mpreal(640320), 3.0 * k + 1.5);
denominator = denominator * mpz_class(three_k_fact * k_fact * k_fact * k_fact).get_mpz_t();
// Ensure denominator is never zero
if (denominator == 0) {
std::cerr << "Error: Division by zero at k = " << k << std::endl;
exit(0);
}
// Compute term: numerator / denominator
term[tid] = numerator.get_mpz_t() / denominator;
} else { // otherwise use t(k+n) = f(k,n) * t(k)
// n = k - previous_k
long n = k - previous_k[tid];
// num_factor = ∏(6k+i) * (1 + (545140134 * n)/(545140134 * previous_k + 13591409))
mpreal num_factor = mpreal(1) +
mpreal(545140134) * n / (mpreal(545140134) * previous_k[tid] + mpreal(13591409));
num_factor *= mpreal(factorial_ratio(6 * k, 6 * previous_k[tid]).get_mpz_t());
// denom_factor = ∏(3k+i) * (∏(k+i))^3 * 640320^(3 * n)
mpz_class denom_factor = factorial_ratio(k, previous_k[tid]);
denom_factor = denom_factor * denom_factor * denom_factor;
denom_factor *= factorial_ratio(3 * k, 3 * previous_k[tid]);
mpz_class temp = 640320;
mpz_pow_ui(temp.get_mpz_t(), temp.get_mpz_t(), 3 * n);
denom_factor *= temp;
term[tid] *= num_factor / denom_factor.get_mpz_t();
// sign of term is (-1)^k
term[tid].setSign(k % 2 != 0 ? -1: 1);
}
previous_k[tid] = k;
// Accumulate thread-local sum
partial_sums[tid] += term[tid];
}
mpreal sum(0);
// Reduce all thread-local sums into a single sum
for (int i = 0; i < NUM_THREADS; i++) {
sum += partial_sums[i];
}
// Compute final pi: pi = 1 / (sum * 12)
mpreal pi = 1 / (sum * 12);
return pi;
}
/**
* @brief Main function.
*
* The entry point of the program. It handles command-line arguments
* setting up global settings and timing the computation.
*
* @return int Returns 0 on successful execution.
*/
int main(int argc, char **argv) {
if (argc > 1)
DIGITS = atoi(argv[1]);
PRECISION = (DIGITS * 4); // Precision in bits (~3.3 decimal digits per bit)
NUM_TERMS = (DIGITS / 14 + 2); // each additional term contributes about 14.18 decimal digits to π
if (std::thread::hardware_concurrency() != 0)
NUM_THREADS = std::thread::hardware_concurrency();
double start_time = omp_get_wtime();
mpreal pi = compute_pi_chudnovsky();
double end_time = omp_get_wtime();
cout << setprecision(DIGITS) << pi << endl;
printf("Computation Time: %f seconds\n", end_time - start_time);
return 0;
}
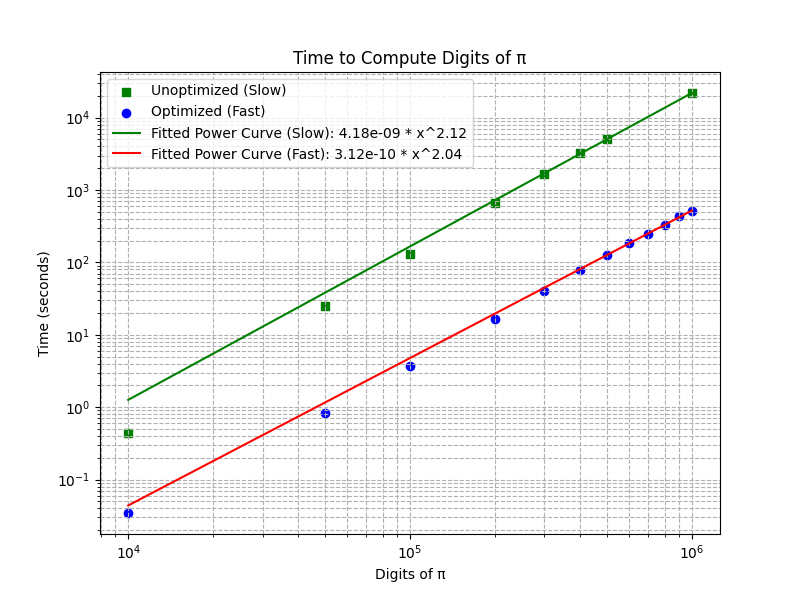
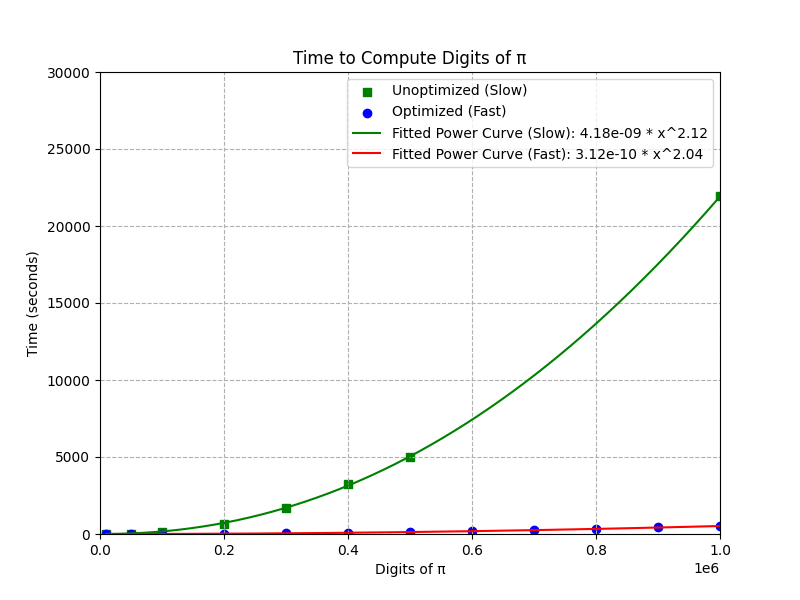
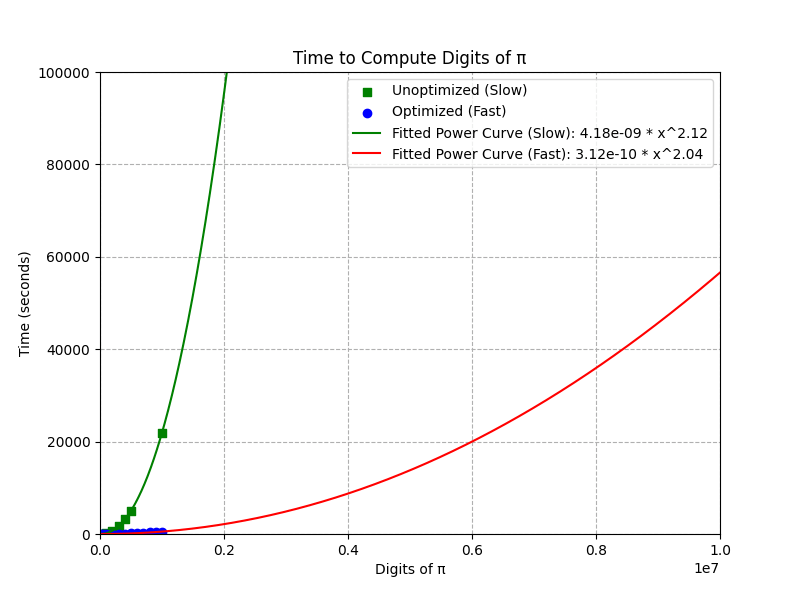
Comparing run times for the unoptimized vs the optimized version of our program we see that the optimization has made a bit improvement. The first graph shows a nearly linear relationship in log-log space suggesting a power relationship. Even though our data is best fit by a power function in both cases, the optimized version has reduced the power slightly. We can see in the middle graph, that the unoptimized version grows much more rapidly than the optimized version. Unfortunately the optimized version is still \(O(n^2)\) which means that if we project out to even larger numbers of digits we see that the quadratic growth will make it difficult to compute π as the number of digits increase. If only there was an algorithm that was closer to \(O(n)\) that we could use.
Spigot Algorithms
Unlike series summation methods like the Chudnovsky formula, which require computing all preceding digits before reaching later ones, spigot algorithms generate digits sequentially without needing to sum the entire series. One such algorithm, developed by Stanley Rabinowitz and Stan Wagon, efficiently produces decimal digits of π. It operates using only integer arithmetic, eliminating the need for multi-precision math. A key advantage is that once a digit is generated, it is no longer required for subsequent computations. However, the algorithm does require an array of 32-bit integers approximately three times the number of desired digits. Despite this, its memory demands are significantly lower than those of the Chudnovsky formula.
spigot.cpp
/**
* @file spigot.cpp
* @brief Program to compute π.
*
* This program can compute π using the decimal spigot algorithm
* of Rabinowitz and Wagon.
*
* http://stanleyrabinowitz.com/bibliography/spigot.pdf
*
* Syntax: spigot <num_digits>
*
* Compile with command:\n
* g++ --std=c++20 -O3 spigot.cpp -o spigot
*
* @author Richard Lesh
* @date 2025-08-13
* @version 1.0
*/
#include <chrono>
#include <iostream>
#include <string>
#include <thread>
#include <vector>
using namespace std;
/**
* @brief Computes the first \p n_digits digits of π using the spigot algorithm.
*
* This function implements the base-10 spigot algorithm to generate the digits
* of π sequentially without requiring arbitrary-precision arithmetic libraries.
* It produces a decimal string of π starting with "3.", followed by
* \p n_digits decimal digits.
*
* ### Algorithm overview
* - Uses an integer array \c A of length
* \f$N = \frac{10 \cdot n\_digits}{3} + 1\f$
* initialized with 2s to perform the iterative spigot steps.
* - At each iteration:
* - Multiplies each element by 10 and propagates the carry from right to left.
* - Updates \c A[0] with the remainder of the final carry.
* - Handles digit emission rules, including:
* - **nines buffering** — sequences of 9s are buffered until confirmed.
* - **predigit correction** — handles cases when a carry of 10 occurs.
* - Skips the first two generated digits ("3.").
*
* @param n_digits Number of decimal digits of π to generate after the decimal point.
* @return A string containing "3." followed by \p n_digits digits of π.
*
* @note This function dynamically allocates a C-style character array
* internally to store the output and then returns it as an
* `std::string`.
*
* @warning The caller must ensure that \p n_digits is non-negative.
* Very large values may result in long runtimes and high memory usage.
*
* @see https://en.wikipedia.org/wiki/Spigot_algorithm
*/
string spigot_pi(int n_digits) {
char* s = new char[n_digits + 2];
int N = (10 * n_digits / 3) + 1; // Size estimate of the array
vector<int> A(N, 2); // Initialize array with 2s
int nines = 0, predigit = 0;
int skipFirst = 2;
s[0] = '3';
s[1] = '.';
char* sp = s + 2;
for (int i = 0; i < n_digits; ++i) {
int carry = 0;
for (int j = N - 1; j >= 0; --j) {
int num = A[j] * 10 + carry * (j + 1);
A[j] = num % (2 * j + 1);
carry = num / (2 * j + 1);
}
A[0] = carry % 10;
carry = carry / 10;
// Handle 9s and predigit corrections
if (carry == 9) {
++nines;
} else if (carry == 10) {
*(sp++) = predigit + 1 + '0';
for (int k = 0; k < nines; ++k) *(sp++) = '0';
predigit = 0;
nines = 0;
} else {
if (skipFirst) --skipFirst;
else *(sp++) = predigit + '0';
predigit = carry;
if (nines > 0) {
for (int k = 0; k < nines; ++k) *(sp++) = '9';
nines = 0;
}
}
}
*(sp++) = predigit;
*sp = '\0';
return string(s);
}
/**
* @brief Entry point for the spigot-based π digit generator.
*
* This program computes the first \p n digits of π using the
* spigot algorithm, measures the computation time, and outputs
* both the digits and the runtime.
*
* The program expects one command-line argument:
* - \p n — The number of digits of π to compute.
*
* ### Usage
* ```
* ./spigot <n>
* ```
*
* **Example:**
* ```
* ./spigot 1000
* ```
* This will compute the first 1000 digits of π and print them
* along with the computation time in seconds.
*
* @return 0 on success.
*
* @warning No input validation is performed beyond `atoi()`. Passing
* non-numeric or negative values will yield undefined behavior.
*
* @see spigot_pi()
*/
int main(int argc, char **argv) {
int n = atoi(argv[1]);
auto start = chrono::high_resolution_clock::now(); // Start timer
string pi = spigot_pi(n);
auto end = chrono::high_resolution_clock::now(); // End timer
chrono::duration<double> duration = end - start; // Compute duration
cout << pi << endl;
cout << "Computation time: " << duration.count() << " seconds" << endl;
return 0;
}
One disadvantage of this spigot algorithm is that it cannot be parallelized like the Chudnovsky algorithm can. This means that it can be a good performance test for a singe CPU, it can't be used to test the performance of a multiple CPU system.
Digit Extraction Algoritms
Another type of algorithms are the digit extraction algorithms. They don’t need to compute the digits from the beginning like spigot algorithms do. Instead these algorithms directly compute the digit at a specified position without computing all the prior digits. One of the first discovered digit extraction algorithm is the BBP (Bailey–Borwein–Plouffe) algorithm. It is a digit extra algorithm that can compute arbitrary hexadecimal (base-16) digits of π. This makes it unique among traditional π algorithms.
The BBP algorithm was discovered in 1995 by Simon Plouffe. It is defined as:
\[\pi = \sum_{k=0}^{\infty} \frac{1}{16^k} \left( \frac{4}{8k+1} - \frac{2}{8k+4} - \frac{1}{8k+5} - \frac{1}{8k+6} \right)\]
How BBP Works
- The formula is used to compute the nth hexadecimal digit of π.
- The computation is done in modular arithmetic, which allows skipping previous digits.
- Since it works in base-16, the output is a sequence of hexadecimal digits.
- The modular exponentiation step ensures that intermediate values remain manageable.
There are a couple of tricks that we need to compute the nth hexadecimal digit of π using this series. The first is to multiply the series by \(16^n\) to get:
\[16^n\pi = \sum_{k=0}^{\infty} \frac{16^n}{16^k} \left( \frac{4}{8k+1} - \frac{2}{8k+4} - \frac{1}{8k+5} - \frac{1}{8k+6} \right) = \sum_{k=0}^{\infty} 16^{n-k} \left( \frac{4}{8k+1} - \frac{2}{8k+4} - \frac{1}{8k+5} - \frac{1}{8k+6} \right)\]
What this does is to give us a value where the integer part of the result is unimportant and the first four bits after the binary point (dividing line between the integer and fractional part of the result) represent the hexadecimal digit in the nth position of π.
The next trick is to divide the series terms into two separate series: one series of terms where \(16^{n-k}\) is a positive integer and another tail series where \(16^{n-k}\) is a fraction less than 1. Because the first series grows to a very large value we want to reduce it. We can do this by taking \(16^{n-k}\) mod the denominator of each term in the series. This impacts the integer part of the series result but since we don’t care about the integer part, we are only concerned with the fractional part, this trick helps us keep things manageable in the first series. The tail series terms are all multiplied by a fraction \(16^{n-k}\) that rapidly decreases making the tail series converge quickly. The fractional part of the first series, plus the fractional only second tail series combined form our result. We can then multiply the fractional part of the result by 16 to move our hexadecimal digit into the integer portion that can then be picked off by using floor(). Here is that trick in equation form.
\[16^n\pi = \sum_{k=0}^{n} 16^{n-k} \left( \frac{4}{8k+1} - \frac{2}{8k+4} - \frac{1}{8k+5} - \frac{1}{8k+6} \right) + \sum_{k=n+1}^{\infty} 16^{n-k} \left( \frac{4}{8k+1} - \frac{2}{8k+4} - \frac{1}{8k+5} - \frac{1}{8k+6} \right)\]
For each \(j \in \{1,4,5,6\}\), compute:
\[S(j,n)=\sum_{k=0}^{n}\frac{16^{n-k}\bmod(8k+j)}{8k+j}+\sum_{k=n+1}^{\infty}\frac{16^{n-k}}{8k+j}\]
then
\[16^{n} \pi = \{4S(1,n) - 2S(4,n) - S(5,n) - S(6,n)\} \]
These computations can easily be done with double precision IEEE 754 math. You can repeatedly multiply the fractional part of this result by 16 to peel off up to 8 hex digits before the limitations of double precision arithmetic introduces errors in the fractional part.
bbp.cpp
/**
* @file bbp.cpp
* @brief Program to compute hexadecimal digits of π.
*
* This program can specific hexadecimal digits of π
* using the Bailey–Borwein–Plouffe formula.
* https://en.wikipedia.org/wiki/Bailey%E2%80%93Borwein%E2%80%93Plouffe_formula
*
* Syntax: bbp <position>
*
* Compile with command:\n
* g++ -std=c++20 -O3 -o bbp bbp.cpp
*
* @author Richard Lesh
* @date 2025-08-13
* @version 1.0
*/
#include <cmath>
#include <cstdint>
#include <iomanip>
#include <iostream>
#include <limits>
#include <mutex>
#include <stdexcept>
#include <string>
#include <semaphore>
#include <ThreadPool.hpp>
using namespace std;
/**
* @brief Computes the modular exponentiation of \f$16^{e} \bmod m\f$.
*
* This function calculates \f$16^{e} \bmod m\f$ using the
* binary exponentiation (exponentiation by squaring) method.
* It uses a 128-bit intermediate type to safely handle
* intermediate products without overflow during multiplication.
*
* @param e The exponent. The function computes 16 raised to this power.
* @param m The modulus. Must be greater than zero. If m == 1, the function returns 0.
* @return The value of \f$16^{e} \bmod m\f$, as a 64-bit unsigned integer.
*
* @note Uses GCC/Clang extension type `__uint128_t` for intermediate
* arithmetic to avoid overflow of 64-bit multiplication results.
* @warning If m == 0, the behavior is undefined (division by zero in modulus).
*
* @see https://en.wikipedia.org/wiki/Modular_exponentiation
*/
uint64_t pow16_mod(uint64_t e, uint64_t m) {
if (m == 1) return 0;
__uint128_t result = 1;
__uint128_t base = 16 % m;
while (e > 0) {
if (e & 1) result = (result * base) % m;
base = (base * base) % m;
e >>= 1;
}
return static_cast<uint64_t>(result);
}
/**
* @brief Returns the fractional part of a floating-point number.
*
* This function extracts and returns the fractional part of the given
* double-precision value \p x, preserving its sign.
* For positive numbers, the result is in the range [0, 1).
* For negative numbers, the result is in the range (-1, 0].
*
* Internally, it uses std::modf from <cmath> to split the number into
* its integer and fractional components.
*
* @param x The input floating-point value.
* @return The fractional part of \p x, with the same sign as \p x.
*
* @note If you need the non-negative fractional part in [0, 1) for
* negative inputs, use std::fabs() on the result.
*
* @see std::modf
*/
inline double frac(double x) {
double intPart;
double fracPart = std::modf(x, &intPart);
return fracPart;
}
/**
* @brief Computes the BBP sub-series S(j, n) for π digit extraction.
*
* This function calculates the sub-series:
* \f[
* S(j, n) = \sum_{k=0}^{n} \frac{16^{n-k} \bmod (8k+j)}{8k+j}
* + \sum_{k=n+1}^{\infty} \frac{16^{n-k}}{8k+j}
* \f]
* where only the fractional part of the result is retained.
*
* The computation is split into two parts and executed in parallel:
* - **Part 1 (k = 0..n)**: Uses modular exponentiation to compute
* \f$16^{n-k} \bmod (8k+j)\f$ exactly, avoiding loss of precision
* for large \p n. The intermediate sum keeps only the fractional
* part to prevent growth.
* - **Part 2 (k = n+1..∞)**: Computes the rapidly converging tail
* sum using floating-point arithmetic until terms drop below
* \f$10^{-24}\f$ in magnitude.
*
* @param j The BBP series parameter (1, 4, 5, or 6 in the main π formula).
* @param n The starting digit position (0-based) in base-16 for the BBP term.
* @return The fractional part of \f$S(j, n)\f$, in the range [0, 1).
*
* @note This implementation uses a thread pool to compute the two
* parts in parallel, synchronizing with a counting semaphore.
* @note The precision target (~1e-24) is sufficient for extracting
* 8 consecutive hexadecimal digits of π at the given position.
*
* @warning The parameter \p j must be a positive integer; for the BBP
* π formula it should be 1, 4, 5, or 6. Behavior is undefined
* if \p m = 8k+j equals zero (which cannot happen for valid \p j).
*
* @see pow16_mod(), frac()
*/
double bbp_series(int j, int64_t n) {
shared_ptr<ThreadPool> pool = ThreadPool::getThreadPool();
counting_semaphore<numeric_limits<int>::max()> semaphore(0);
// Part 1: k = 0..n using modular arithmetic for exactness
double s = 0.0;
mutex prefix_mutex;
int tasks = 0;
int task_size = 100000;
for (int64_t t = 0; t <= n; t += task_size) {
++tasks;
pool->enqueue([&s, &prefix_mutex, &semaphore,
t, task_size, n, j]() {
double local_s = 0.0;
int64_t n_end = min(t + task_size - 1, n);
for (uint64_t k = t; k <= n_end; ++k) {
const uint64_t m = 8 * k + j;
const uint64_t e = n - k;
const uint64_t r = pow16_mod(e, m);
// Add r/m to s, keep only fractional part to limit growth
local_s = frac(local_s + static_cast<double>(r) / static_cast<double>(m));
}
lock_guard<mutex> lock(prefix_mutex);
s = frac(s + local_s);
semaphore.release();
});
}
// Part 2: k = n+1..∞ using floating tail (rapidly convergent)
// Each successive term is 16 times smaller.
double t = 0.0;
++tasks;
pool->enqueue([&t, &semaphore, n, j]() {
const double ln16 = log(16.0);
// We sum until terms are below ~1e-24
for (int64_t k = n + 1; ; ++k) {
double power = expl(static_cast<double>(n - k) * ln16); // 16^(n-k) = 16^{-(k-n)}
double term = power / static_cast<double>(8 * k + j);
if (term < 1e-24) break;
t += term;
}
semaphore.release();
});
for (int i = 0; i < tasks; ++i)
semaphore.acquire();
return frac(s + t);
}
/**
* @brief Computes and prints 8 hexadecimal digits of π starting at a given position.
*
* This function uses the Bailey–Borwein–Plouffe (BBP) digit extraction formula
* to calculate 8 consecutive hexadecimal digits of π beginning at the
* 0-based digit position \p n after the hexadecimal point.
*
* The BBP formula for π is:
* \f[
* \pi = \sum_{k=0}^\infty \frac{1}{16^k}
* \left( \frac{4}{8k+1} - \frac{2}{8k+4}
* - \frac{1}{8k+5} - \frac{1}{8k+6} \right)
* \f]
*
* This function evaluates the four independent BBP sub-series
* \f$ S(1, n), S(4, n), S(5, n), S(6, n) \f$ in parallel using a thread pool,
* then combines them as:
* \f[
* frac\left(4S(1,n) - 2S(4,n) - S(5,n) - S(6,n)\right)
* \f]
* where \f$frac()\f$ denotes taking the fractional part. The resulting
* fractional value is multiplied by 16 repeatedly to extract 8 hex digits.
*
* @param n Zero-based starting position of the first hexadecimal digit after
* the hexadecimal point (e.g., \p n = 0 yields digits 1–8 after the point).
*
* @return the 8 hexadecimal digits computed
*
* @note The four BBP sub-series are computed concurrently via a shared
* thread pool and synchronized with a counting semaphore.
*
* @note Only the fractional part of the result is needed for digit extraction,
* so intermediate sums are reduced to [0, 1) to preserve precision.
*
* @warning This implementation assumes \p n is non-negative and that the
* `bbp_series()` function provides sufficient precision for the
* required digits.
*
* @see bbp_series(), frac()
*/
string bbp_hex_digits(int64_t n) {
shared_ptr<ThreadPool> pool = ThreadPool::getThreadPool();
counting_semaphore<4> semaphore(0);
double s1;
pool->enqueue([&s1, &semaphore, n]() {
s1 = bbp_series(1, n);
semaphore.release();
}, 100);
double s4;
pool->enqueue([&s4, &semaphore, n]() {
s4 = bbp_series(4, n);
semaphore.release();
}, 100);
double s5;
pool->enqueue([&s5, &semaphore, n]() {
s5 = bbp_series(5, n);
semaphore.release();
}, 100);
double s6;
pool->enqueue([&s6, &semaphore, n]() {
s6 = bbp_series(6, n);
semaphore.release();
}, 100);
semaphore.acquire();
semaphore.acquire();
semaphore.acquire();
semaphore.acquire();
double x = 4.0 * s1 - 2.0 * s4 - s5 - s6;
x = frac(x); // fractional part of pi * 16^n
// Extract 8 hex digits
static const char *HEX = "0123456789ABCDEF";
string out;
out.reserve(8);
for (int i = 0; i < 8; ++i) {
// Pull slightly away from 1.0 boundary to avoid accidental carry
x = std::nextafter(x, 0.0);
x = ldexp(x, 4); // x *= 16 (exact)
int d = static_cast<int>(floor(x));
x = x - d;
out.push_back(HEX[d & 0xf]);
}
return out;
}
/**
* @brief Entry point for the BBP π hexadecimal digit extractor.
*
* This program computes and prints 8 consecutive hexadecimal digits of π
* starting at a given position after the hexadecimal point, using the
* Bailey–Borwein–Plouffe (BBP) digit extraction algorithm.
*
* The program expects exactly one command-line argument:
* - \p position: The 0-based index of the first hex digit to compute after
* the point. For example, a position of 0 prints the first 8 hex digits
* after the point; a position of 5 prints digits 6–13 after the point.
*
* ### Usage
* ```
* ./bbp <position>
* ```
*
* **Example:**
* ```
* ./bbp 0 # Prints the first 8 hex digits of π
* ./bbp 100000 # Prints 8 hex digits starting at position 100,000
* ```
*
* @return `0` on success, non-zero on error (invalid arguments, parse error, etc.).
*
* @throws std::invalid_argument if the position argument contains non-numeric characters.
* @throws std::out_of_range if the position is too large to fit in a 64-bit unsigned integer.
*
* @see bbp_hex_digits()
*/
int main(int argc, char **argv) {
try {
if (argc != 2) {
cerr << "Usage: " << argv[0] << " <position>\n"
<< " position = 0-based index of the first hex digit after the point.\n"
<< "Example: " << argv[0] << " 0 # prints first 8 hex digits\n";
return 1;
}
// Parse as unsigned 64-bit
string arg = argv[1];
size_t pos = 0;
int64_t n = stoull(arg, &pos, 10);
if (pos != arg.size())
throw invalid_argument("Non-numeric characters in position");
auto start = chrono::high_resolution_clock::now(); // Start timer
string digits = bbp_hex_digits(n);
auto end = chrono::high_resolution_clock::now(); // End timer
chrono::duration<double> duration = end - start; // Compute duration
cout << digits << "\n";
cout << "Computation time: " << duration.count() << " seconds" << endl;
} catch (const exception &e) {
cerr << "Error: " << e.what() << "\n";
return 1;
}
return 0;
}
Because we are computing four \(S(j, n)\) series, each which is composed of two series, we can split the computation across 8 threads to speed up the computation as we do in the previous code example.
A faster method based on the same principles as the BBP algorithm is the Bellard formula. It requires about 43% fewer terms to reach the same precision.
\[\pi = \frac{1}{2^6} \sum_{n=0}^{\infty} \frac{(-1)^n}{2^{10n}} \left( -\frac{2^5}{4n+1} -\frac{1}{4n+3} +\frac{2^8}{10n+1} -\frac{2^6}{10n+3} -\frac{2^2}{10n+5} -\frac{2^2}{10n+7} +\frac{1}{10n+9} \right)\]
bellard.cpp
/**
* @file bellard.cpp
* @brief Program to compute hexadecimal digits of π.
*
* This program can specific hexadecimal digits of π
* using the bellard formula.
* https://en.wikipedia.org/wiki/Bellard%27s_formula
*
* Syntax: bbp <position>
*
* Compile with command:\n
* g++ -std=c++20 -O3 -o bellard bellard.cpp
*
* @author Richard Lesh
* @date 2025-08-13
* @version 1.0
*/
#include <chrono>
#include <cmath>
#include <iomanip>
#include <iostream>
#include <limits>
#include <semaphore>
#include <string>
#include <ThreadPool.hpp>
using namespace std;
/**
* @brief Returns the fractional part of a floating-point number.
*
* This function extracts and returns the fractional part of the given
* double-precision value \p x, preserving its sign.
* For positive numbers, the result is in the range [0, 1).
* For negative numbers, the result is in the range (-1, 0].
*
* Internally, it uses std::modf from <cmath> to split the number into
* its integer and fractional components.
*
* @param x The input floating-point value.
* @return The fractional part of \p x, with the same sign as \p x.
*
* @note If you need the non-negative fractional part in [0, 1) for
* negative inputs, use std::fabs() on the result.
*
* @see std::modf
*/
inline double frac(double x) {
double intPart;
double fracPart = std::modf(x, &intPart);
return fracPart;
}
/**
* @brief Computes the modular exponentiation of \f$2^{e} \bmod m\f$.
*
* This function calculates \f$2^{e} \bmod m\f$ using the
* binary exponentiation (exponentiation by squaring) method.
* It uses a 128-bit intermediate type to safely handle
* intermediate products without overflow during multiplication.
*
* @param e The exponent. The function computes 2 raised to this power.
* @param m The modulus. Must be greater than zero. If m == 1, the function returns 0.
* @return The value of \f$2^{e} \bmod m\f$, as a 64-bit unsigned integer.
*
* @note Uses GCC/Clang extension type `__uint128_t` for intermediate
* arithmetic to avoid overflow of 64-bit multiplication results.
* @warning If m == 0, the behavior is undefined (division by zero in modulus).
*
* @see https://en.wikipedia.org/wiki/Modular_exponentiation
*/
uint64_t pow2_mod(uint64_t e, uint64_t m) {
if (m == 1) return 0;
__uint128_t result = 1;
__uint128_t base = (2 % m);
while (e) {
if (e & 1) result = (result * base) % m;
base = (base * base) % m;
e >>= 1;
}
return static_cast<uint64_t>(result);
}
/**
* @brief Adds a rational value to an accumulator and reduces the result to its fractional part.
*
* This helper function adds the fraction \f$\frac{r}{m}\f$ to the accumulator \p acc
* and replaces \p acc with its non-negative fractional part in the range [0, 1).
* It is typically used in modular summations where only the fractional portion
* of the running sum is needed, such as in BBP- or Bellard-type digit extraction
* formulas for π.
*
* @param acc Reference to the accumulator to be updated. On return, it contains
* the fractional part of the updated sum.
* @param r Numerator of the fraction to add.
* @param m Denominator of the fraction to add (must be non-zero).
*
* @note This function calls `frac()` to perform the fractional part extraction,
* ensuring the value stays within [0, 1) to preserve precision in long
* iterative summations.
*
* @warning Behavior is undefined if \p m is zero.
*
* @see frac()
*/
inline void add_frac(double &acc, mutex &mut, int64_t r, int64_t m) {
lock_guard<mutex> lock(mut);
acc = frac(acc + static_cast<double>(r) / static_cast<double>(m));
}
/**
* @brief Computes the fractional contribution of one term family in Bellard’s π formula.
*
* This helper function evaluates the partial sum of terms of the form:
* \f[
* \sum_{n=0}^{\infty} (-1)^n \cdot \frac{2^{\,4p - 6 - 10n + \text{shift_c}}}{a n + b}
* \cdot \text{sign_c}
* \f]
* where:
* - \f$p\f$ is the starting hexadecimal digit position (0-based after the point)
* - \f$a\f$ and \f$b\f$ define the linear denominator \f$a n + b\f$
* - \f$\text{shift_c}\f$ adjusts the power-of-two coefficient (e.g., 8 for \f$2^8\f$)
* - \f$\text{sign_c}\f$ is +1 or -1 for the term’s overall sign
*
* ### Algorithm
* 1. **Split at the modular boundary**:
* - The base-2 exponent \f$E_2(n) = 4p - 6 - 10n + \text{shift_c}\f$.
* - For \f$E_2(n) \ge 0\f$, compute \f$2^{E_2(n)} \bmod (a n + b)\f$ exactly
* using `pow2_mod()` and accumulate the result modulo 1 with `add_frac()`.
* - This ensures full precision for large \f$p\f$ before the exponent turns negative.
* 2. **Floating-point tail**:
* - For \f$E_2(n) < 0\f$, evaluate the rapidly converging tail terms
* in `double` precision until the term magnitude falls below \f$10^{-24}\f$,
* which is sufficient for 8 hex digit accuracy.
* - The sign is adjusted by \f$(-1)^n\f$ and \p sign_c.
* 3. **Parallel execution**:
* - The prefix (modular part) and the tail (floating part) are computed
* concurrently in two threads from a shared `ThreadPool`.
* - A counting semaphore synchronizes their completion.
*
* @param p Starting hex digit position (0-based after the point).
* @param a Linear denominator coefficient (e.g., 4 or 10 in Bellard’s formula).
* @param b Linear denominator offset (e.g., 1, 3, 5, 7, 9 in Bellard’s formula).
* @param shift_c Power-of-two shift to apply to the coefficient (e.g., 8 for \f$2^8\f$).
* @param sign_c Overall sign of the term family (+1 or -1).
* @return The fractional contribution of this term family to \f$16^p \pi\f$, in [0, 1).
*
* @note The precision target (~1e-24) is chosen to ensure correctness for 8 hex digits.
*
* @see bellard_hex8(), pow2_mod(), add_frac()
*/
double bellard_component(
int64_t p, // starting hex position
int a, int b, // denominator a*n + b
int shift_c, // power-of-two shift for coefficient (e.g., 8 for 2^8)
int sign_c) { // +1 or -1 for the coefficient’s sign
shared_ptr<ThreadPool> pool = ThreadPool::getThreadPool();
counting_semaphore<numeric_limits<int>::max()> semaphore(0);
// The exponent of two in each term is E2(n) = 4p - 6 - 10n + shift_c
// For E2(n) >= 0 we can do exact modular arithmetic.
// Largest n with non-negative exponent:
int64_t n_mod = static_cast<int64_t>(floor(static_cast<double>(4 * p - 6 + shift_c) / 10.));
//if (n_mod < 0) n_mod = 0; // if exponent is already negative, skip modular loop
// ---- Modular (exact) prefix: n = 0..n_mod ----
double prefix = 0.0;
mutex prefix_mutex;
int tasks = 0;
int task_size = 100000;
for (int64_t t = 0; t <= n_mod; t += task_size) {
++tasks;
pool->enqueue([&prefix, &semaphore, &prefix_mutex,
p, t, task_size, n_mod, a, b, shift_c, sign_c]() {
int64_t n_end = min(t + task_size - 1, n_mod);
for (int64_t n = t; n <= n_end; ++n) {
int64_t denom = a * n + b;
// E2 = 4p - 6 - 10n + shift_c (guaranteed >=0 here)
int64_t E2 = (4 * p - 6 - 10 * n + shift_c);
auto r = static_cast<int64_t>(pow2_mod(E2, denom));
// Apply (-1)^n and overall sign_c by mapping to modulo
if ((n & 1) != 0) r = -r;
if (sign_c < 0) r = -r;
add_frac(prefix, prefix_mutex, r, denom);
}
semaphore.release();
});
}
// ---- Floating tail: n = n_mod+1 .. infinity (rapidly convergent) ----
// Each step shrinks by ~2^10 ≈ 1024, so double is plenty for 8 hex digits.
double tail = 0.0;
++tasks;
pool->enqueue([&tail, &semaphore, p, n_mod, a, b, shift_c, sign_c]() {
const double ln2 = log(2.0L);
for (int64_t n = n_mod + 1; ; ++n) {
int64_t denom = a * n + b;
// Exponent (negative here): E2 = 4p - 6 - 10n + shift_c
const double E2 = static_cast<double>(4 * p - 6 - 10 * n + shift_c);
double term = exp(E2 * ln2) / static_cast<double>(denom); // 2^{E2}/denom
if (term < 1e-24L) break;
if (n & 1) term = -term; // (-1)^n
if (sign_c < 0) term = -term; // overall coefficient sign
tail = frac(tail + term);
}
semaphore.release();
});
for (int i = 0; i < tasks; ++i)
semaphore.acquire();
return frac(prefix + tail);
}
/**
* @brief Computes 8 hexadecimal digits of π starting at a given position
* using Bellard’s formula.
*
* This function implements Fabrice Bellard’s faster BBP-type series for π:
* \f[
* \pi = \frac{1}{2^6} \sum_{n=0}^{\infty} \frac{(-1)^n}{2^{10n}}
* \left(
* -\frac{2^5}{4n+1}
* -\frac{1}{4n+3}
* +\frac{2^8}{10n+1}
* -\frac{2^6}{10n+3}
* -\frac{2^2}{10n+5}
* -\frac{2^2}{10n+7}
* +\frac{1}{10n+9}
* \right)
* \f]
*
* For a given starting hex position \p p (0-based after the hexadecimal point),
* the function computes the fractional part of \f$16^p \pi\f$ in base 16,
* then extracts and returns the next 8 hexadecimal digits.
*
* ### Implementation details
* - The computation is split into 7 independent sub-series terms (the bracketed
* terms above), each handled by `bellard_component()` which returns the
* fractional contribution for the given \p p.
* - The sub-series are dispatched to a shared thread pool and run in parallel,
* with a counting semaphore ensuring all have completed before proceeding.
* - The overall factor of \f$2^{-6}\f$ in Bellard’s formula is already handled
* in each sub-series via the exponent offset, so the accumulated sum is
* directly the fractional part of \f$16^p \pi\f$.
* - When extracting digits, `std::nextafter()` is used to pull values slightly
* away from the 1.0 boundary to prevent rounding anomalies that could cause
* an incorrect carry into the next digit.
* - `ldexp(x, 4)` is used for exact multiplication by 16 when peeling off
* each hex digit.
*
* @param p The starting hex digit position after the point (0-based).
* @return A string of exactly 8 hexadecimal characters representing digits
* \f$p\f$ through \f$p+7\f$ of π in base 16.
*
* @see bellard_component()
* @see std::nextafter()
* @see ldexp()
*/
string bellard_hex8(uint64_t p) {
// pi = (1/2^6) * sum_{n>=0} (-1)^n / 2^{10n} * [ -2^5/(4n+1) - 1/(4n+3)
// + 2^8/(10n+1) - 2^6/(10n+3)
// - 2^2/(10n+5) - 2^2/(10n+7)
// + 1/(10n+9) ]
// We want frac( 16^p * pi ) = frac( 2^{4p} * pi )
// => each component contributes (-1)^n * 2^{4p - 6 - 10n + shift_c} / (a n + b) with sign.
double acc = 0.0L;
shared_ptr<ThreadPool> pool = ThreadPool::getThreadPool();
counting_semaphore<7> semaphore(0);
// Components: (a, b, shift_c, sign_c)
// -2^5/(4n+1)
double b1 = 0.0L;
pool->enqueue([&b1, &semaphore, p]() {
b1 = bellard_component(p, 4, 1, 5, -1);
semaphore.release();
}, 100);
// -1/(4n+3)
double b2 = 0.0L;
pool->enqueue([&b2, &semaphore, p]() {
b2 = bellard_component(p, 4, 3, 0, -1);
semaphore.release();
}, 100);
// +2^8/(10n+1)
double b3 = 0.0L;
pool->enqueue([&b3, &semaphore, p]() {
b3 = bellard_component(p, 10, 1, 8, +1);
semaphore.release();
}, 100);
// -2^6/(10n+3)
double b4 = 0.0L;
pool->enqueue([&b4, &semaphore, p]() {
b4 = bellard_component(p, 10, 3, 6, -1);
semaphore.release();
}, 100);
// -2^2/(10n+5)
double b5 = 0.0L;
pool->enqueue([&b5, &semaphore, p]() {
b5 = bellard_component(p, 10, 5, 2, -1);
semaphore.release();
}, 100);
// -2^2/(10n+7)
double b6 = 0.0L;
pool->enqueue([&b6, &semaphore, p]() {
b6 = bellard_component(p, 10, 7, 2, -1);
semaphore.release();
}, 100);
// +1/(10n+9)
double b7 = 0.0L;
pool->enqueue([&b7, &semaphore, p]() {
b7 = bellard_component(p, 10, 9, 0, +1);
semaphore.release();
}, 100);
for (int i = 0; i < 7; ++i) semaphore.acquire();
acc = frac(b1 + b2 + b3 + b4 + b5 + b6 + b7);
// Multiply by 2^{-6} overall factor already accounted for via (-6) in exponent,
// so acc is already frac( 16^p * pi ).
// Extract 8 hex digits
static const char *HEX = "0123456789ABCDEF";
string out;
out.reserve(8);
double x = frac(acc);
for (int i = 0; i < 8; ++i) {
// Pull slightly away from 1.0 boundary to avoid accidental carry
x = std::nextafter(x, 0.0);
x = ldexp(x, 4); // x *= 16 (exact)
int d = static_cast<int>(floor(x));
x -= d;
out.push_back(HEX[d & 0xF]);
}
return out;
}
/**
* @brief Entry point for the Bellard’s formula π hexadecimal digit extractor.
*
* This program computes and prints 8 consecutive hexadecimal digits of π
* starting at a specified position after the hexadecimal point, using
* Bellard’s faster BBP-type formula.
*
* The program expects exactly one command-line argument:
* - \p position — The 0-based index of the first hexadecimal digit after
* the point to compute. For example:
* - \p position = 0 → prints the first 8 hex digits after the point.
* - \p position = 5 → prints hex digits 6–13 after the point.
*
* ### Usage
* ```
* ./bellard <position>
* ```
*
* **Example:**
* ```
* ./bellard 0 # Prints the first 8 hex digits of π
* ./bellard 1000000 # Prints 8 hex digits starting at position 1,000,000
* ```
*
* The program also measures and prints the computation time in seconds.
*
* @return 0 on success, non-zero on error (invalid arguments or exceptions).
*
* @throws std::invalid_argument if \p argv[1] contains non-numeric characters.
* @throws std::out_of_range if the position value exceeds `uint64_t` range.
*
* @note The computation is performed by the `bellard_hex8()` function, which
* implements Bellard’s formula for digit extraction in base 16.
* @see bellard_hex8()
*/
int main(int argc, char **argv) {
if (argc != 2) {
cerr << "Usage: " << argv[0] << " <position>\n"
<< " position = 0-based hex digit index after the point\n"
<< "Example: " << argv[0] << " 0 # prints first 8 hex digits\n";
return 1;
}
try {
// Parse as unsigned 64-bit
uint64_t pos = stoull(argv[1]);
auto start = chrono::high_resolution_clock::now(); // Start timer
string digits = bellard_hex8(pos);
auto end = chrono::high_resolution_clock::now(); // End timer
chrono::duration<double> duration = end - start; // Compute duration
cout << digits << "\n";
cout << "Computation time: " << duration.count() << " seconds" << endl;
} catch (const exception &e) {
cerr << "Error: " << e.what() << "\n";
return 1;
}
return 0;
}